Philosophy of Software Design - 第七章 不同层,不同抽象
软件系统是由不同层构成的,高层使用底层提供的功能。在一个设计良好的系统中,每一层都提供有别于其他层的抽象,如果你触发一个函数调用并跟踪它在不同层中的操作,就会发现每一层的抽象都会发生变化。比如:
- 在文件系统中,最上层实现了文件抽象。一个文件包含一个可变长的比特数组,并且支持不定长的读写更新。文件系统中低一层的抽象实现了固定大小硬盘块的内存缓存;调用者可以假设频繁使用的块会驻留在内存中以供快速获取。最底层是硬件驱动,负责在二级存储设备和内存之间搬运数据块。
- 在网络传输协议比如 TCP 中,最上层提供的抽象是机器之间可信赖的比特流传输。这是建立在低一层的尽力而为传输服务之上的:大部分数据包都可以成功送达,但是部分包会丢失或者乱序。
7.1 Pass-through 方法
当相邻的层具有相仿的抽象时,问题会以 pass-through 方法的方式表现出来。pass-through 方法的签名和它调用的方法一样或类似,除了调用其他方法基本没有实现别的功能。比如,一个学生项目实现的文本编辑界面中有个类基本都是 pass-through 方法。下面是这个类的摘要:
|
|
这个类里 15 个公共方法,其中 13 个是 pass-through 方法
红色警告 ⚠️: Pass-through 方法
pass-through 方法除了将它的参数传递给另外一个通常是和它签名类似的函数外,不实现任何功能。这是类间的责任划分不明确的典型情况。
pass-through 方法使把类变浅:它们增加了类接口的复杂度,也就是增加了复杂度,对系统整体来说却没有新增任何功能。上面例子中的四个方法,只有最后一个实现了一点功能:检查了参数的有效性。pass-through 方法还会制造类之间的依赖:如果 TextArea 类中的 insertString 签名发生变化,TextDocument 中的 insertString 方法也必须跟着修改。
pass-through 方法意味着类之间的责任划分不明确。在上面的例子中,TextDocumnet 提供了 insertString 方法,但是插入文本的功能完全是在 TextArea 这个类中实现的。这通常是个坏主意:因为一个功能的实现和接口应该在同一个类当中。当你遇到 pass-through 方法时,考虑一下:“这些功能和抽象应该如何由各个类分工实现?”可能就会注意到,这些类之间有重叠。
解决方案是重构类,使它们的实现划分明确且逻辑连贯。图 7.1 展示了几种解决办法。一种办法是,如 7.1(b) 所示,将更低一层类的方法直接暴露给高一层类的调用者,删掉对高一层类中相关实现的依赖。另一种方法是重新分布类中的方法,如图 7.1(c) 所示。最后,如果类无法解耦,最好的办法是像 7.1(d) 中那样将它们合并。
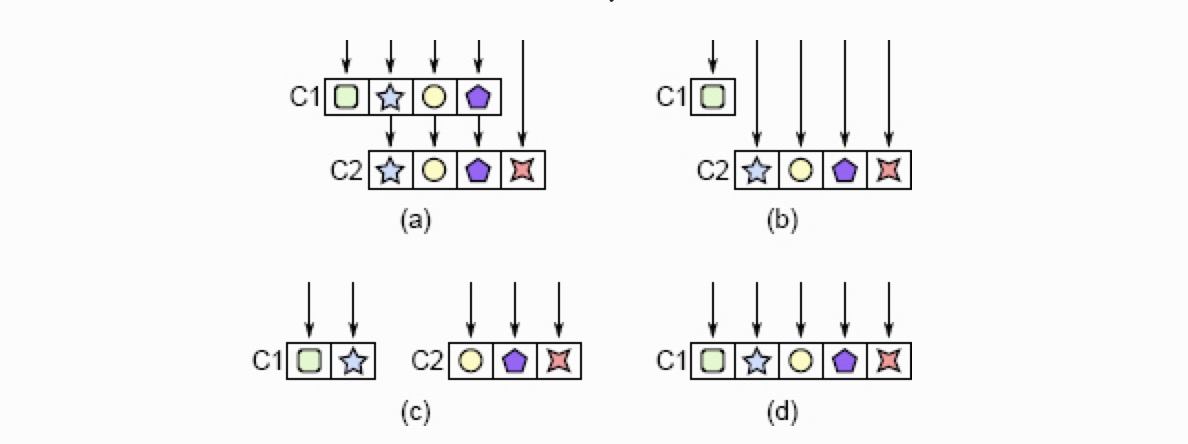
__图 7.1__ pass-through 方法。在 (a) 中,类 C1 包含 3 个 pass-through 方法,除了调用 C2 中相同签名的函数(每个不同的符号代表一个特定的方法签名)外什么都不做。pass-through 方法可以有像下面这样被消除,(b):让 C1 的调用者直接调用 C2 中的方法。(c):重新分布 C1 和 C2 中的方法避免两个类之间互相调用。(d):将两个类合并。
什么时候重复的接口是可以接受的
有相同签名的不同方法并不总是有问题的。重要的是,不同的方法应当提供显著的功能。pass-through 方法不好是因为它们不提供任何新功能。
一个方法调用另外一个相同签名方法,却仍然有用的例子是分发器dispathcer。分发器通过参数来决定调用多个方法中的一个,然后将它的大多数参数传递给被选中的方法。分发器的签名经常和它调用的函数相同。即使这样,分发器依然提供了有用的功能:它决定了每个任务应该由哪个函数完成。
比如,当 Web 服务器接收到来自浏览器的 HTTP 请求时,它会触发分发器,由分发器检查请求中的 URL 以决定由哪个特定方法来处理这个请求。一些 URL 的处理可能是返回磁盘中的文件内容;另外一些可能需要触发其他进程来处理,这些进程中运行着 PHP 或 Javascript。分发的过程可能会相当复杂,而且经常会由一系列和入访的 URL 所匹配的规则所驱动。
只要实现的功能有用且不重复,多个方法具有相同签名也是没问题的。由分发器调用的方法就具有这样的属性。另外的例子是,同一个接口的不同实现,比如不同操作系统的磁盘驱动。每个磁盘驱动提供了对不同磁盘的支持,但是它们有着相同的接口。当不同实现具有相同的接口时,会降低认知负担。当你使用过这些方法中的一种时,再使用其他方法会很简单,因为你不需要再学一种新的接口。具有这种属性的方法通常属于同一层,它们之间不会互相调用。
7.3 修饰器
使用修饰器的目的是把一个类的特殊目的扩展和通用核心实现分离开。然而,修饰器类很容易会变得表面化:他们引入了大量的模版,却只实现了很少的功能。修饰器类通常会包含很多 pass-through 方法(只简单地调用其他方法,本身不包含功能实现)。很容易过度使用修饰器模式,为每个新的小功能创建一个类。这将导致没有深度的类爆炸性增长,就像 Java I/O 那个例子一样。
因此,在创建一个修饰器类之前,先考虑以下备选方案:
- 可以把新功能直接添加在底层类中,而不是创建一个新的修饰器类吗?这种方案在新功能比较有通用性、或与底层功能有逻辑关联、或基本会和底层类同时使用时行得通。比如,基本上只要使用 InputStream 就会使用 BufferedInputStream,而且缓存是 I/O 的一个自然组成部分,所以这些类应该被合并到一起。
- 如果新功能是为了一个特定的使用场景添加的,是否可以把它放在相应的场景实现中,而不是新创建一个类?
- 可以把新功能放在已有的修饰器中吗?从而得到一个单个的更深的修饰器,而不是多个很浅的。
- 最后,新的功能真的需要封装已有的功能吗:可以作为一个独立于底层类的单独功能来实现吗?在创建窗口的例子中,下拉条或许可以直接单独实现而不依赖主窗口、不封装所有它已有的功能。
有时修饰器行得通,但是总会有一个更好的备选方案。
7.4 接口和实现
“不同层、不同抽象”规则的另一个应用就是类的接口和实现一般来说应该不同:内部使用的表述应该区别于接口中的抽象。如果这两者有相似的抽象,那么这个类可能不够有深度。比如,在第六章中讨论的文本编辑工程,大部分团队通过每行单独存储来实现文本模块,其中一些团队还提供了围绕行的文本类 API,比如 getLine 和 putLine。然而,这使得文本类很浅而且难以使用。在高层的用户交互代码中,在一行的中间插入文本(比如用户正在输入)或删除跨行的文本是非常常见的。使用面向行的文本类 API 时,调用者不得不拆分和组合行来实现用户交互的功能。这些代码并不简单,而且重复并且分散在交互功能的各处。
当提供基于字符的 API 时,文本类可以变得好用的多,比如可以在文本中任意位置插入随意多个字符串(可以包含新的一行)的 insert 方法,以及可以删除任意两个位置之间的文本的 delete 方法。在类内部,文本依旧以行的形式表述。基于字符的接口封装了拆分和组合行的复杂性,使得文本类更具深度,并且简化了使用文本类的高层代码。这种实现方式里,文本类的 API 和基于行存储的实现机制相当不同;这种不同代表了由文本类提供的有价值的功能。
7.5 Pass-through 变量
另一种跨层 API 重复的形式是 pass-through 变量,即在方法调用链中传递的变量。图 7.2 中展示了一个来自数据中心服务的例子,命令行参数指定了安全通信中所需的证书。这个参数只有底层函数 m3 在调用酷函数打开 socket 时会使用,但是却从 main 函数到 m3 一路被传递下来。cert 变量出现在所有中间函数的签名中。
由于 pass-through 变量导致中间函数都需要知晓它的存在,从而增加了复杂度。而且,如果需要增加新的变量(比如有的系统本来设计时没有对证书的支持,但是后期又决定加入),你可能需要修改大量的接口和函数,以将变量传递下去。
消除 pass-through 变量是非常有挑战的。一种办法是,看下最顶层到最底层的函数现在是否已经有共享的对象。在图 7.2 所示的数据中心服务的例子中,可能有一个对 main 和 m3 都可见的对象,它可以包含关于网络通信的更多的信息。如果有的话,main 函数可以将证书信息存储在那个对象中,这样就不需要从 main 经过调用链路上的所有中间函数传递到 m3 了(如图 7.2(b))。然而,如果存在这样一个对象的话,那么它本身可能就是一个 pass-through 变量(要不然 m3 是怎么获取到它的呢?)
另外的办法是,将信息存在一个全局变量中,如图 7.2(c) 所示。这样就避免了将信息在方法间传递的麻烦,但是全局变量几乎总是制造其他的麻烦。比如,由于访问全局变量时会冲突,使得在同一个进程中为系统创建两个独立的实例变得不可能。可能在生产环境不需要多个实例,但是在测试环境却是很有用的。
我经常使用的解决方案是像图 7.2(d)那样引入上下文(context)对象。一个上下文对象存储了应用中所有的全局状态(任何其他情况下可能是 pass-through 变量或全局变量的东西)。大多数应用的全局状态都会有多个变量,代表了配置选项、共享子系统以及性能计数器等。系统的每个实例都有各自的上下文对象。上下文对象使得系统的多个实例在同一个线程中得以共存。
不幸的是,可能很多地方都需要用到上下文对象,这使得它可能变成 pass-through 变量。为了减少需要知道上下文对象存在的函数的数量,上下文对象的引用可以存储在系统的大多数主要对象中。在图 7.2(d) 的例子中,m3 方法所在的类,在它生成的对象中以实例变量的方式存储了指向上下文对象的引用。当创建新对象时,创建方法会从它的对象中获取引用并传递给新对象的构造函数。通过这种方法,上下文对象只在构造函数的参数中显式出现,却是随处可得的。
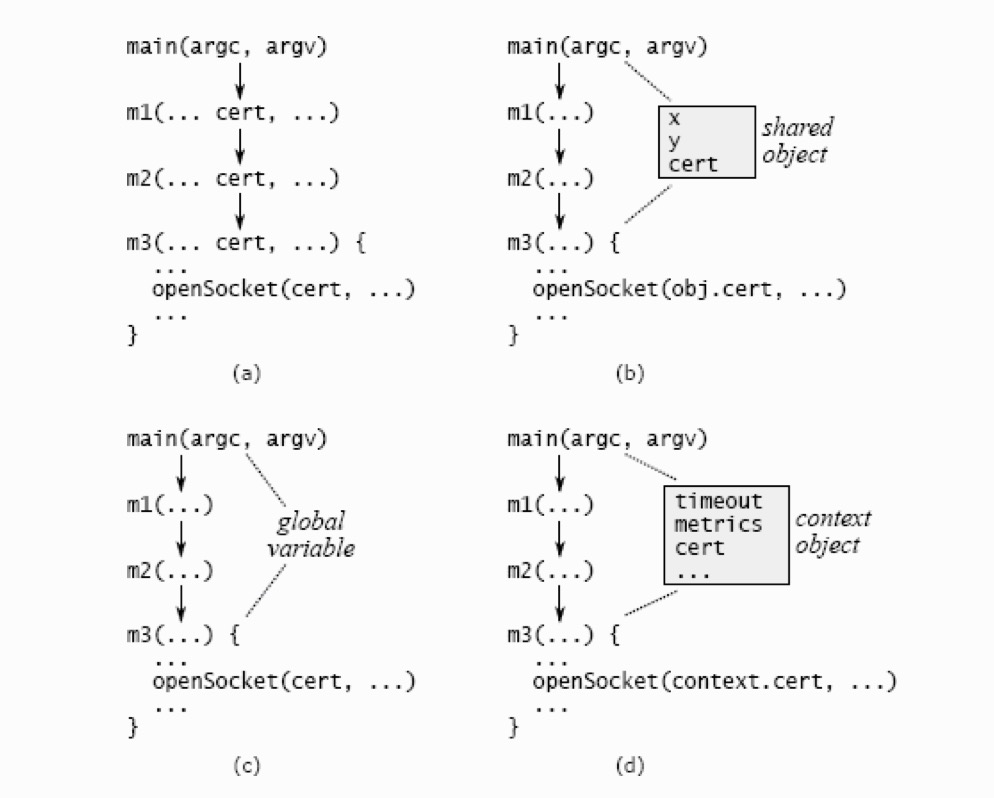
__图 7.2__ 处理 pass-through 变量可能的技术方案。(a) `cert` 在函数`m1` `m2` 间传递,即使它们使用不到。 (b) 将`cert` 变量存储在 `main` 和 `m3` 的共享对象中,这样变量就不需要通过 `m1` 和 `m2` 传递了。(c) 将 `cert` 变量存储为全局变量 (d) 将 `cert` 变量和其他系统级变量比如超时时间 `timeout` 性能计数器 `performance counters` 一起存储在上下文对象中。所有需要用到这些变量的对象都会存储一份上下文对象的引用。
上下文对象使得所有对系统级可见的信息的处理变得方便,并且消除了 pass-through 变量。如果需要新增一个变量,可以将它放入上下文对象中;除了上下文对象的构造和析造函数,现有的代码不会受影响。上下文对象使得鉴别和管理全局状态变得容易,因为它们都在同一个地方。使用上下文对象也为测试带来了方便:测试代码可以通过修改上下文对象中的属性改变全局配置。在使用 pass-through 变量的系统中这是非常难以做到的。
上下文远非完美的解决方案。全局变量的缺点,上下文对象中存储的变量大部分都有;比如,某个变量为什么会出现、会在哪里使用可能会不太好搞懂。没有约定的话,上下文对象可能会变成一个贯穿了整个系统、制造着不明依赖的的超大数据包袱。另外也可能导致线程安全的问题;解决问题最好的办法是上下文中的变量都不可变。不幸的是,我还没有找到比上下文更好的解决方案。
7.6 结论
系统中每新增一个基础的设计组件,比如接口、方法、参数、函数、类或定义,就会增加系统的复杂度,因为开发者需要学习这个组件。为了使新增的组件相较于复杂度提供更多的功能,这个组件必须可以解决某些没有它时的复杂度。否则,你最好在实现系统时去掉这个组件。比如,类可以通过封装功能来降低复杂度,这样用户在使用这个类时,不需要有这些功能的知识。
「不同层、不同抽象」的规则只是这个主旨的一个应用:如果不同层有相同的抽象,比如 pass-through 方法或装饰器,那么有很大可能它们并不能提供足够的便利来抵消额外引入的机制。类似地,pass-through 参数要求多个方法知道它的存在,却没有提供任何功能。