操作系统导论学习笔记(六)
地址转换的二次尝试:分段
打破三个 简化假设 中的第一条:「用户的地址空间必须连续地放在物理内存中」。在 MMU 中引入不止一个基址和界限寄存器,而是给地址空间内的每个逻辑段(segment)一对。在典型的地址空间里,有 3 个逻辑不同的段:代码段、栈和堆。

段寄存器的值
分段机制 使得操作系统可以将不同的段放到不同物理内存区域,避免了地址空间中未使用的部分占用内存。
分段的地址空间示意图 在物理内存中放置段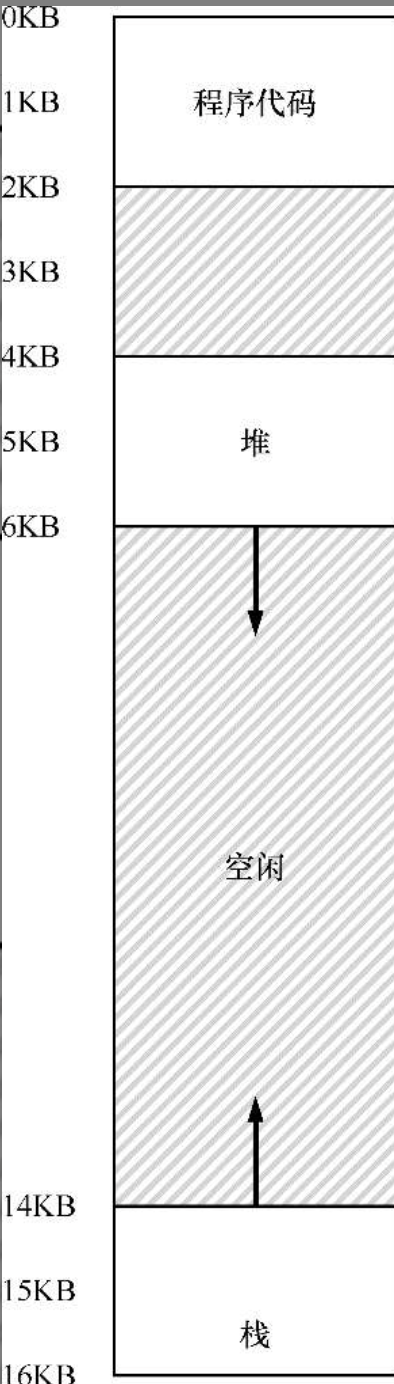
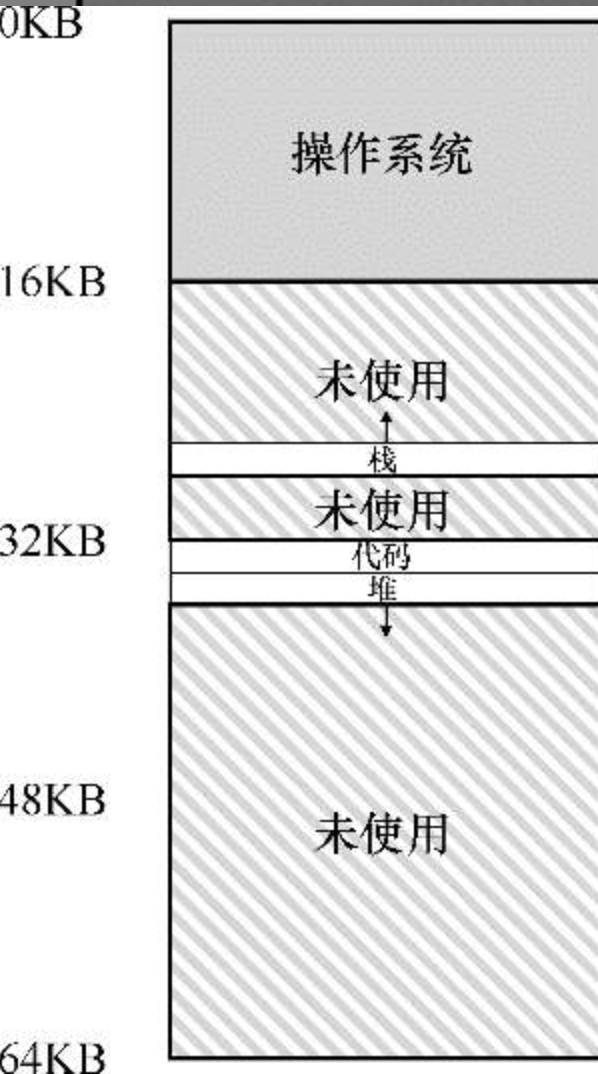
计算地址转换时,需要先减去地址空间中的偏移,比如要访问堆的虚拟地址为 4200, 需要先减去地址空间中 4k 的偏移量,然后再根据基址寄存器中得到实际地址:4200-4096+34816=34920
分段的引入的问题:虚拟地址属于哪个段
将地址空间分段映射后,除了需要多对基址和界限寄存器,还需要辨识要访问的地址属于哪个段
显式方式:
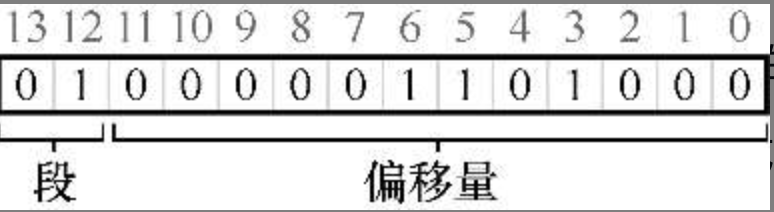
虚拟地址 4200 的二进制形式
在虚拟地址中,前 2 位用于标识属于哪个段,上图中 01 表示属于堆,后面是段内偏移量,0000 0110 1000(即十六进制 0x068 或十进制 104 ),然后和基址寄存器中的地址相加得到物理地址 104+34816=34920
有的实现中,会把堆和栈当作一个段,这样就只有两个段,只需要一个标识位。
隐式方式:
硬件通过地址产生方式来判断属于哪个段,如果地址由程序计数器( PC 指针)产生,那么无疑是代码段,如果基于栈或基址指针,那么这个虚拟地址在栈段,其他情况则来自堆段。
分段的引入的问题:栈段增长方向
栈的增长方向和代码段以及堆不一样,是反向增长的,比如栈被分配到 28k 地址,大小为 2k, 那么结束地址是 26k,因此需要硬件支持:新增一位标识地址是否反向增长。
分段的引入的问题:共享
随着分段机制的改进,内存使用效率纳入考虑,如果内存可以跨地址空间共享,可以明显提升使用率,对于代码段这种只读形式的内存,完全可以由操作系统同时映射到多个地址空间中,而不会担心隔离遭到破坏。
如果要支持内存共享,则需要区分内存的访问方式(只读、读写、可执行等),段寄存器再追加一位保护位,如下图所示。
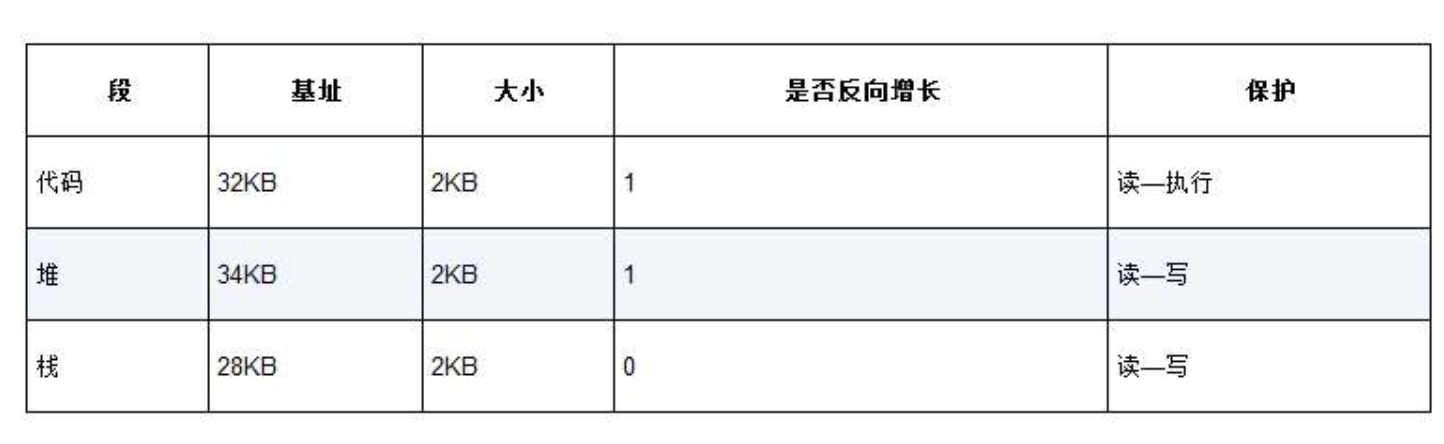
段寄存器的值(有保护位)
另外,地址转换算法也需要改进,除了判断是否越界,还需要检查特定访问是否允许:如果用户试图写入只读区域,或从非执行段执行指令,硬件会触发异常,让操作系统来处理出错进程。
分段:小结
代码段、栈、堆这种划分段的方式是 粗粒度(coarse grained),相对的,有的操作系统支持将地址空间划分为成千上万的段,这种是 细粒度(fine grained)。
细粒度的分段方式有助于操作系统更灵活地使用内存。
有了分段的支持,堆和栈之间未使用的地址空间,不再需要分配物理内存,从而提高了内存利用率。但是也给操作系统带来了新问题:
- 上下文切换时,操作系统需要额外保存和恢复段寄存器中的内容
- 管理空闲空间变得复杂:之前假设地址空间大小都相同,现在一个进程中的不同分段大小都可能不同,这样物理内存会被使用的很零散,很快充满了许多空闲的小洞,很难分配新的段,也无法扩容已有的段,这种问题被称为外部碎片
解决外部碎片有两种思路:
- 重新整理紧凑内存:操作系统停止进程运行,然后将分散的已分配内存整理、拷贝到连续的内存空间中,但是内存密集型操作,占用大量处理器时间
- 利用空闲内存管理算法:试图保存大的内存块用于分配,有非常多的算法,也说明没有特别好的算法来解决这个问题。
解决外部碎片最根本的方案是,消除产生的原因:不要分配大小不一的内存块
分段要求的算法简单易实现,提高了稀疏地址空间的内存利用率,并且带来了共享部分分段(主要指代码段)的好处,但是分段大小不一带来了外部碎片的问题,而且如果某个逻辑分段中地址空间本身就非常稀疏(比如堆空间申请和实际使用相差很大),这种情况分段是无法提高内存利用率的。
空闲空间管理
关键问题:如何管理空闲空间
要满足变长的分配请求,应该如何管理空闲空间?什么策略可以让碎片最小化,不同方法的时间和空间开销如何?
用户程序中管理堆,操作系统管理进程的地址空间,都需要用到空闲空间管理。在开始具体的讨论之前,我们先做一些假设:
- 聚焦于用户程序中的堆管理,类似 malloc 和 free 调用,free 只接受一个指针变量,因此管理方需要根据指针得到要释放的内存大小
- 只关心外部碎片
- 调用 malloc 分配内存返回指针后,地址就固定了,不可以移动,因此不能通过整理内存来减少碎片
- 管理的内存是一片连续的区域,并且整个应用生命周期期间空间不变
底层机制
底层机制需要解决 3 个问题:
- 内存的分割与合并:在空闲管理列表(链表)中记录空闲块的起始地址与块大小,分配内存时修改起始地址及块大小称为内存分割,内存释放时,会检查是否有连续的空间,如果有就将列表中的空闲块进行合并,称为内存合并
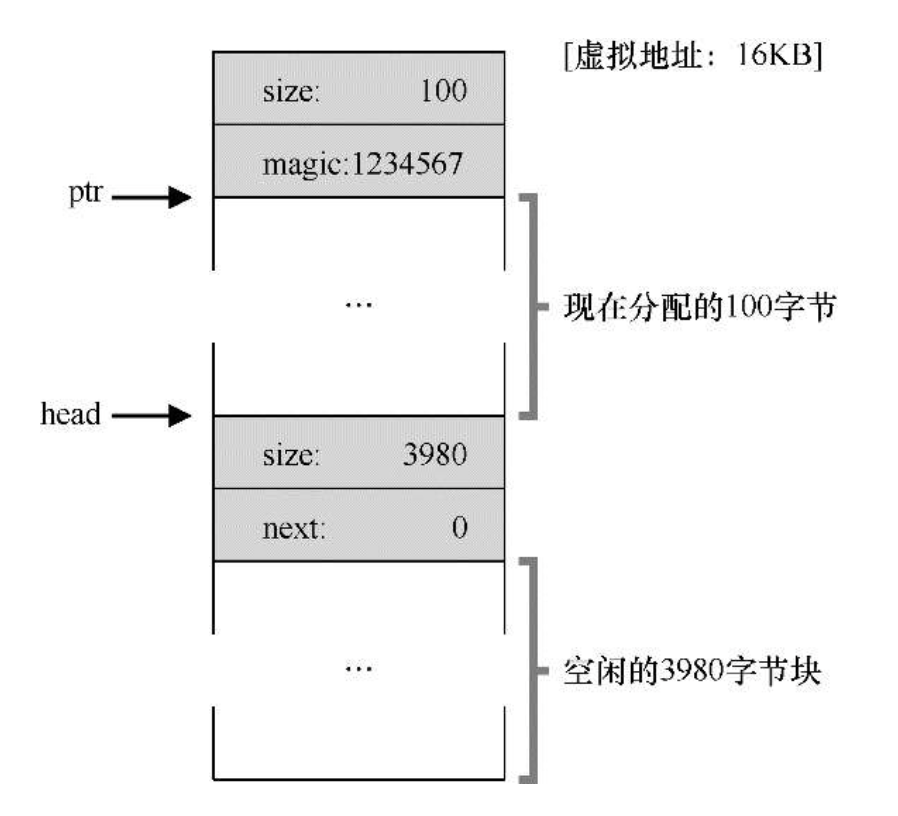
- 追踪已分配内存大小:在分配的内存块中划分出一片头块(header)来记录分配内存大小,内存完整性校验值等,因此用户申请大小为 N 的内存块时,实际需要寻找 N+header 大小的区域分配,释放时也是同理。
- 在哪里存储空闲管理列表:在空闲空间本身中,通过头块,建立空闲空间列表
空闲空间管理逻辑链表示意图
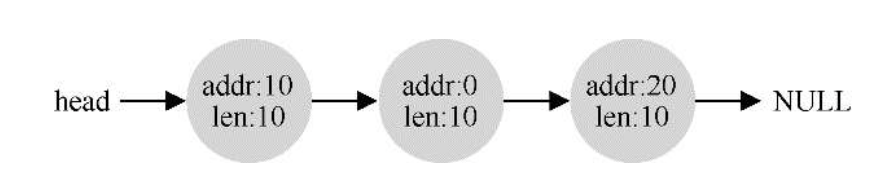
经过分配又释放后的空闲内存管理链表(未合并)
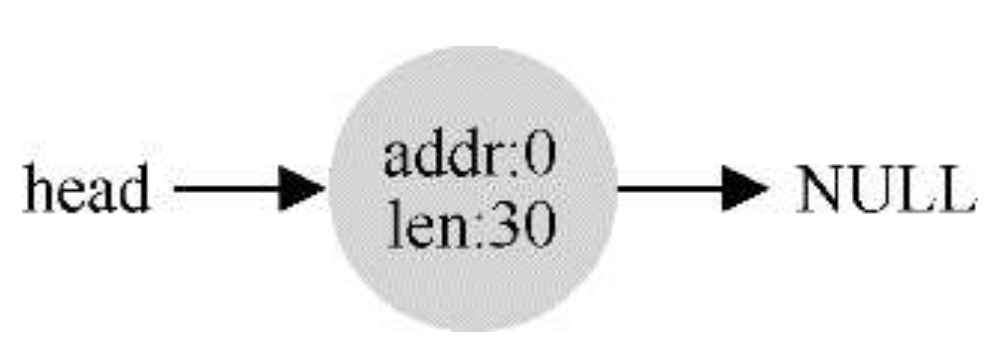
合并后的空闲内存管理链表(和初始化时相同)
分配头块后的内存区域示意图,hptr 和 ptr 之间是 malloc 库使用的头块
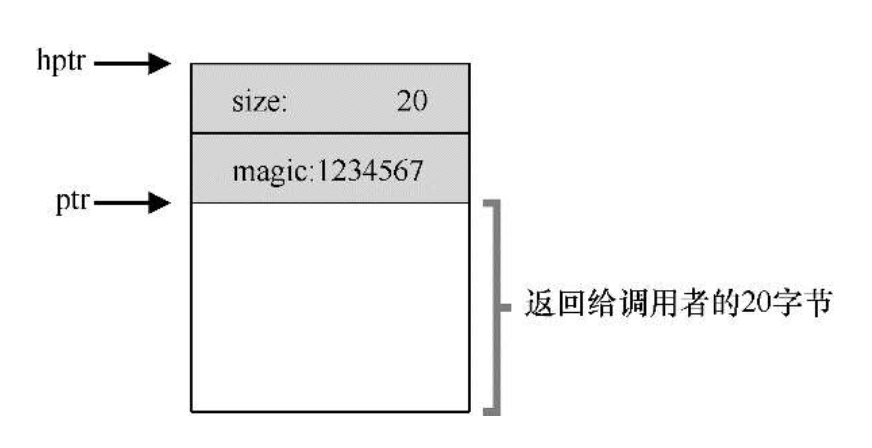
一个已分配的区域加上头块
实际的空闲空间管理列表存储示意图
-
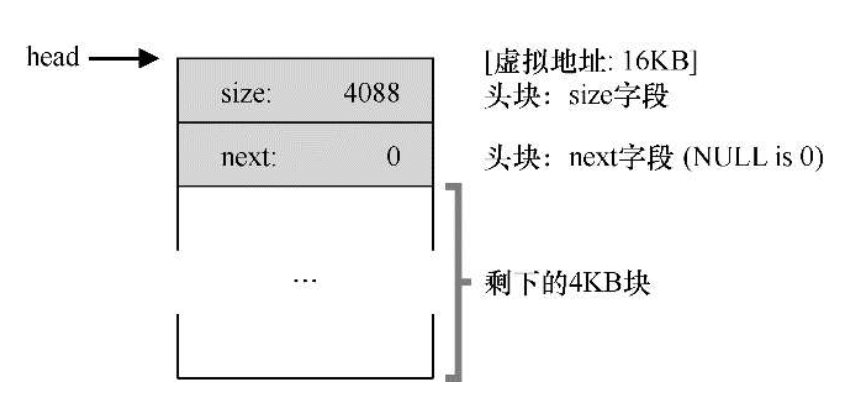
1-有一个空闲块的堆.png
-
2-在一次分配之后的堆.png
-
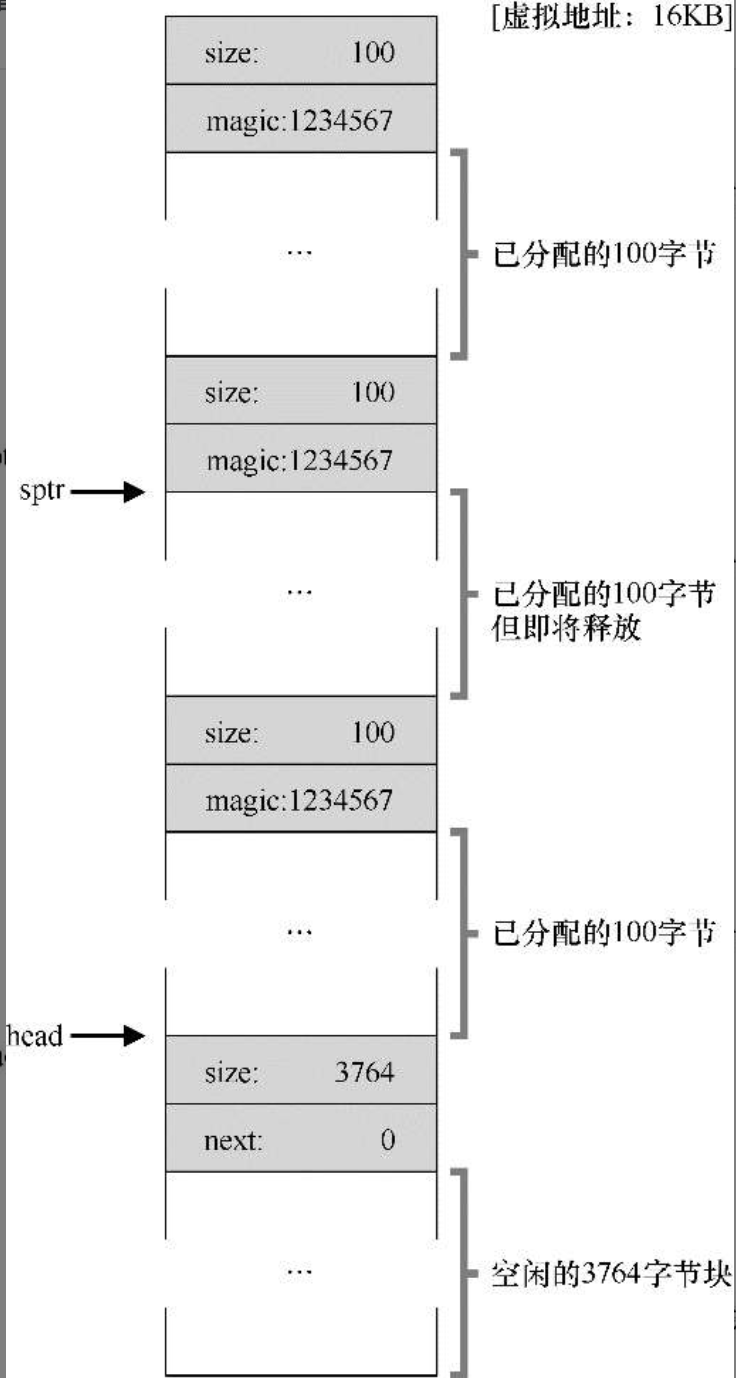
3-空闲空间和 3 个已分配块.png
-
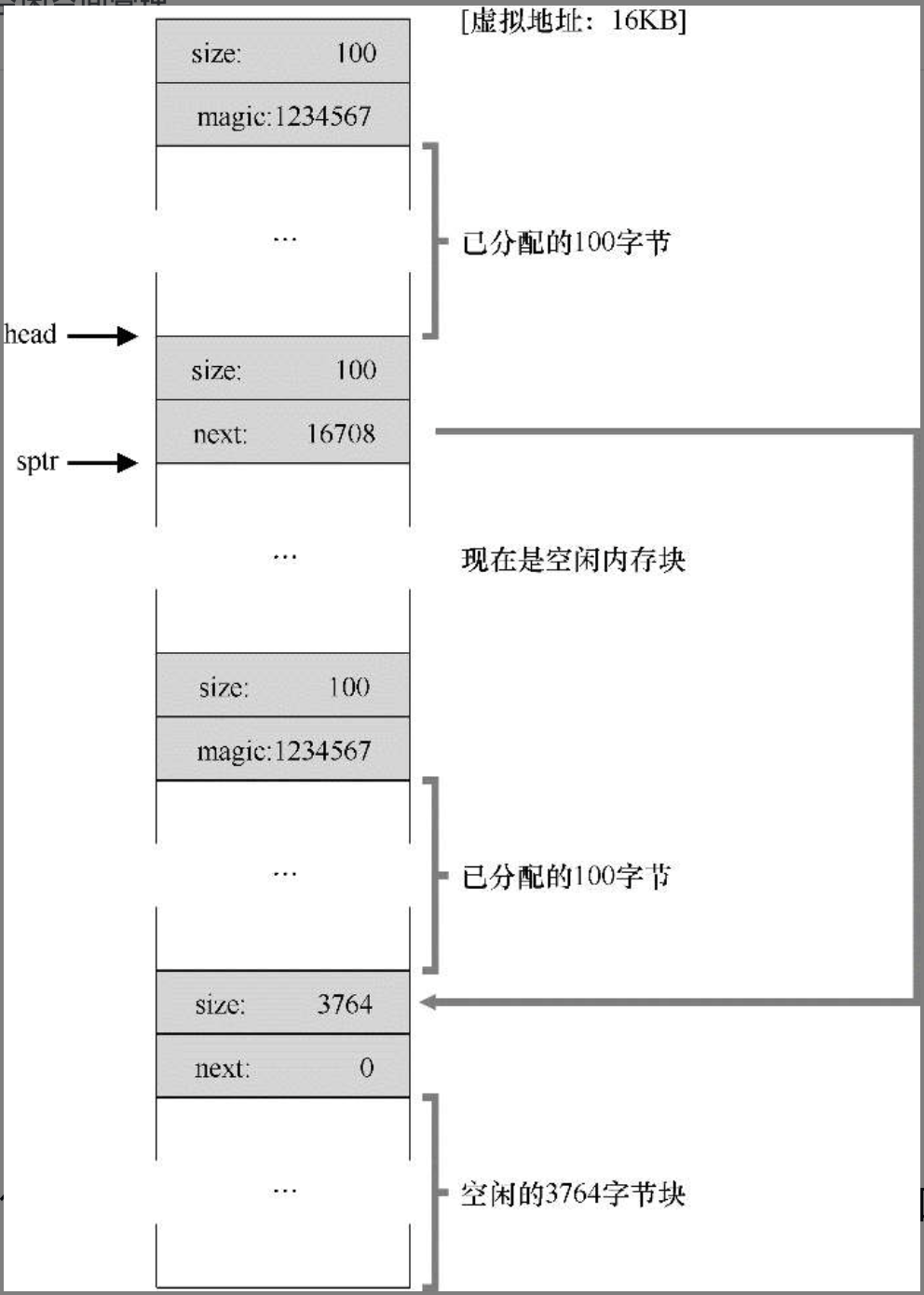
4-空闲空间和 2 个已分配块.png
-
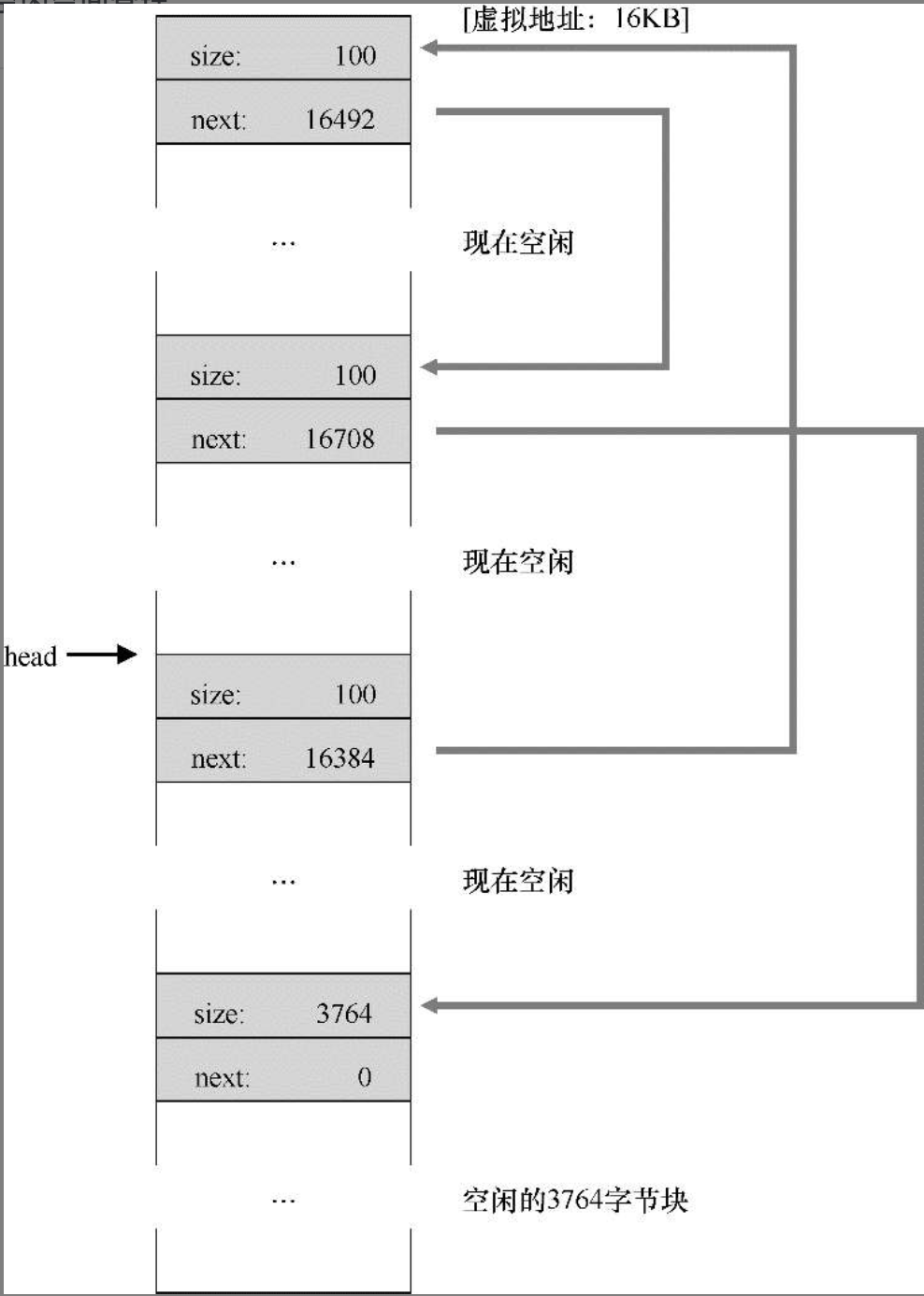
5-全部空间已释放但未合并的空闲空间列表.png
如果用户申请内存时,堆中内存已耗尽,那么有两种处理方式:
- 直接返回 NULL
- 向操作系统申请新的空间映射到进程地址空间中(大多数 Unix 系统中,是通过 sbrk 系统调用)
基本策略
理想的分配程序可以保证快速和碎片最小化,但是由于申请及释放的随机性,没有最好的策略,只有特定情况会更合适的策略
- 最优匹配 best fit:遍历整个空闲列表,找到和申请内存大小最接近的空闲块返回。优点是内存浪费小,缺点是由于需要全部遍历而性能降低,并且可能剩下很多无法利用的小块
- 最差匹配 worst fit:找到最大的空闲块,分割满足用户需求后,将余下的块放回空闲列表。同样需要遍历列表,尝试在空闲列表中留下最大的块,但是表现往往很糟糕
- 首次匹配 first fit:遇到第一个满足需求的空闲块时,按需求分割内存返回,将剩余的块放回空闲列表。有速度优势,但有时会让列表头部频繁的分割,充满内存碎片
- 下次匹配 next fit:为了解决首次匹配头部频繁分割的问题,多一个指针记录上次分配的位置,再次申请时从这个位置开始寻找,将查找操作扩散到整个空闲列表中