ElasticSearch 学习记录
ES 的基本概念
- 使用 lucene 作为核心搜索库,倒排索引
index索引,类似于 sql 中的一张表,具有相似数据结构的 document 构成一个 indexdocument文档,类似于 sql 表中的一条数据,含有多个 fieldfield类似于 sql 表中的一列,属性及其值node/clusteres 可以在不同的机器(node)上运行不同的线程,组成 cluster 的形式提供服务shard每个 es 进程中可以有多个 shard,每个 index 可以切分到多个 shard 中保存,为了防止数据丢失,shard 可以有一个 primary shard 和多个 replica shard
ES 的分布式架构
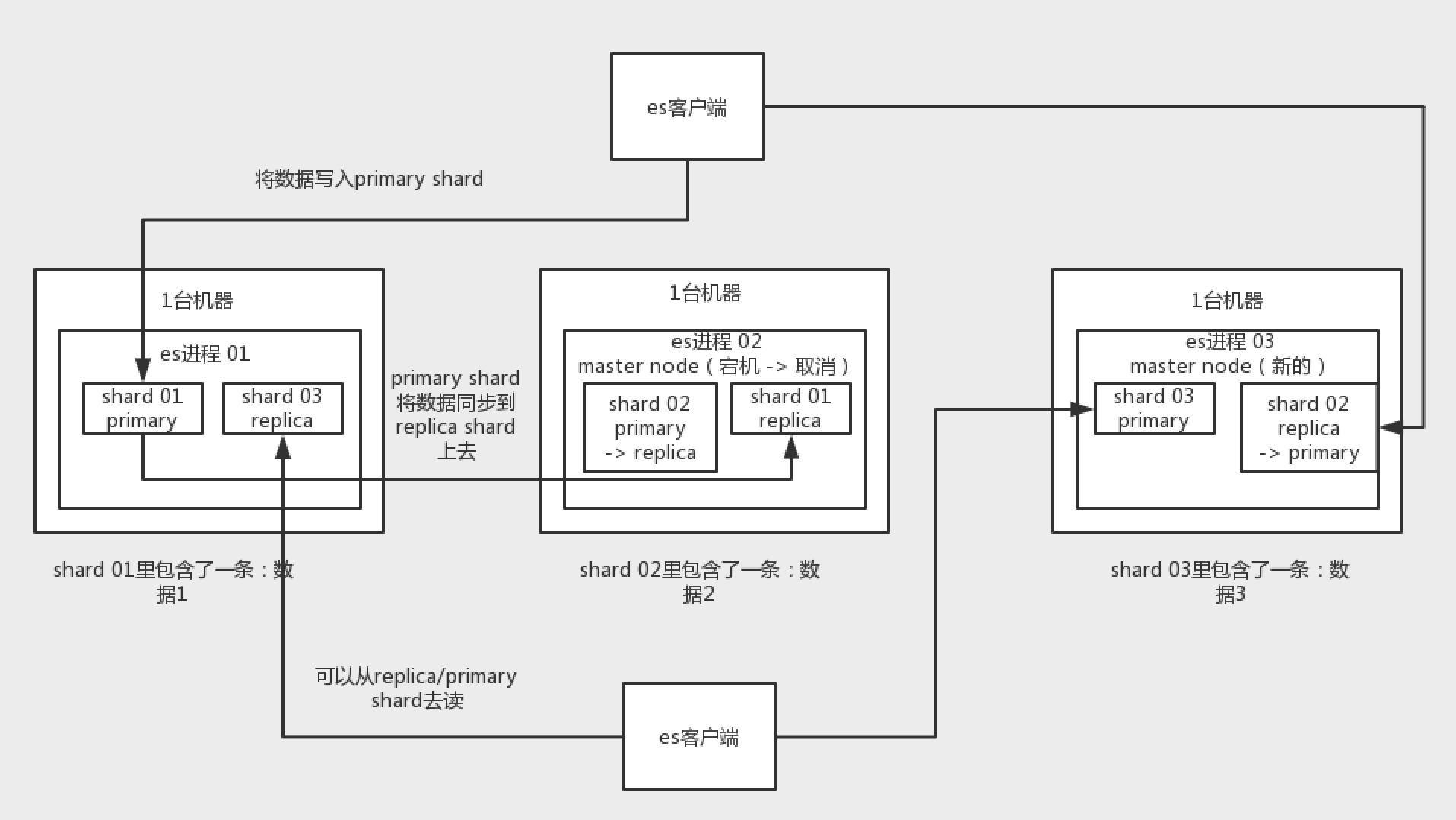
- 不同的 shard 不会保存 index 的全部数据,而是每个 shard 会保存一部分
- 一个 shard 的 primary/replica 会在不同机器上,当一台机器挂掉后,可以从另一台机器的 shard 中读取/恢复数据
- 写入 es 时,会向 primary shard 写,primary shard 同步到 replica shard,同步成功后返回写入成功到客户端
- 读 es 时,可以从 primary shard 读,也可以从 replica 读
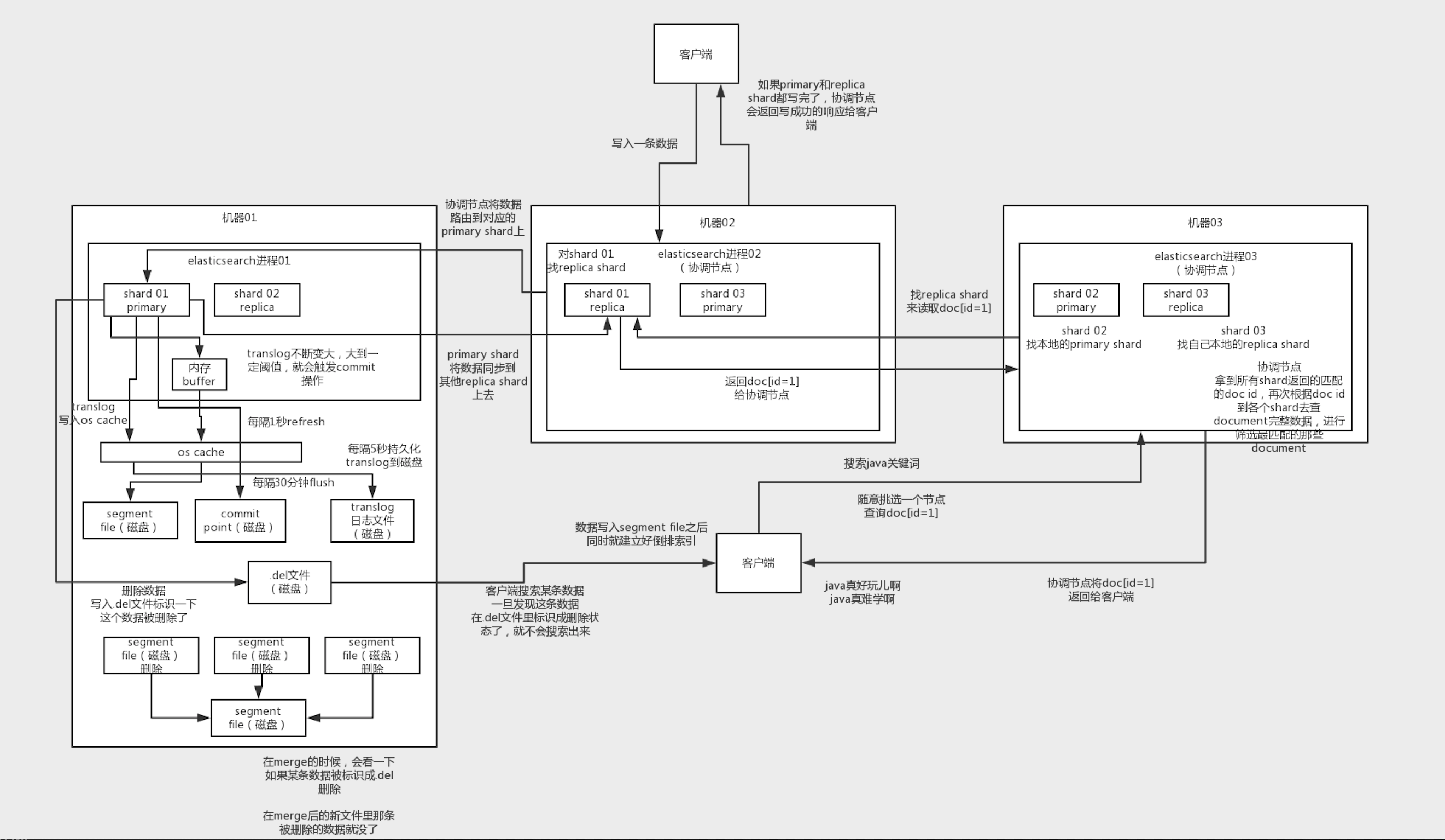
ES 的写过程
- 客户端发起一条数据的写请求,到随意一个机器比如机器 02,02 此时便作为协调节点(coordinating node)发挥作用
- 协调节点对数据进行哈希,根据结果将数据路由到对应的 primary shard (称为 shard A)所在的节点
- shard A 接收到数据后,进行存储,并同步到 replica shard
- 协调节点等待 shard A 的写入和同步都完成后,向客户端发送写入成功回执
shard A 写数据过程详细
-
shard A 收到数据后,会先缓存到内存 buffer 中,并写入一份到 translog1 文件的系统缓存(os cache),此时,该条数据虽然写入完成,但是没有经过进一步处理,客户端进行查询的话,是查询不到的
-
buffer 写满/每隔一段时间(默认 1s),es 将 buffer 中的数据 refresh 到 segment file 的 os cache 中,数据写入 segment file 之后,同时就会建立好倒排索引,若 buffer 中没有数据则跳过
-
由于 os cache 虽然不是 es 在管理,但也是内存,如果机器挂掉数据同样会丢失,所以 os cache 超过一定容量/每隔一段时间(默认 30min)会 flush 到磁盘,此时将会生成多个 segment file(上次 flush 到这次之间 refresh 个数的)
-
translog 同样需要持久化,达到一定阈值/每隔一段时间(默认 5s)进行一次 commit 操作
- 将 buffer 中的数据 refresh 到 os cache 中,清空 buffer
- 将一个 commit point 写入磁盘文件,里面标识着这个 commit point 之前的所有 segment file
- 将 os cache 中的所有数据强制 fsync 到磁盘
-
由于每次 refresh 操作,都会生成一个 segment file,所以数量会急剧增多,到达一定阈值后,会触发 merge 操作,合并为一个大的 segment file,并将原来的小文件删除
-
es 删除数据是标记删除,即删除请求到达后,会记录一个 .del 的磁盘文件,当搜索某条数据时,一旦发现在 .del 文件中被标记为删除,则不会返回;在 merge 被触发后,过程中检查 segment file 中的记录是否已经被标记删除,若是,则不会进入大的 segment file,以此达到删除的目的
ES 的读过程
es 读数据分为两种
- 根据 doc id 进行 get 查询
- 搜索
查询
- 客户端向协调节点发起查询请求
- 协调节点根据 doc id 进行哈希,获得该条数据所在 shard 及其 node
- 由于查询既可以向 primary 也可以向 replica 发起,因此这里选取路由时有一个 lb,从中选取一个 shard 及其 node 即可
- shard 将数据返回给协调节点,协调节点将数据返回客户端
搜索
- 客户端向协调节点发起搜索请求
- 协调节点将关键词发给所有 shard(primary/replica 任选其一)
- 各个 shard 根据关键词进行搜索,并返回匹配度较高的几条 doc 的 id 给协调节点
- 协调节点接收到所有 shard 的返回后,根据匹配度进行排序,获取最优的几条,并根据 doc id 向 shard 查询对应的 document,返回给客户端
Ps. ES 是准实时的,因为在 buffer 中的内容 refresh 到 segment file 之前是搜索不到的,大概会有 1s 的时间差
Ps.s. ES 有可能会丢数据,在 buffer、translog 中有数据未落盘时机器宕机
Ps.s.s. refresh、flush、commit 操作都可以通过 rest API/Java API 手动触发
参考资料:
中华石杉码农,视频资料
-
translog 的作用:机器宕机重启时,会读取 translog 中的信息,并恢复到内存 buffer 和 os cache 中,减少数据丢失。 ↩︎